






Acmeware Achieves 100% Submission Success
Featured article
Acmeware completes 100% successful submissions for eCQM, PQRS, Hospital IQR, and Joint Commission ORYX using OneView for acute and ambulatory settings.
Understanding how MEDITECH organizes data across applications is the essential first step for Data Repository report writing. DR mirrors MEDITECH's application structure, with table naming conventions that reflect each module (REG, ADM, BAR, LAB, etc.).
As an experienced Data Repository report writer, it's easy to take for granted how much knowledge someone may have about MEDITECH, or assume that hospital IT staff simply know certain things. This was glaringly apparent to me when teaching an introductory DR report writing class recently. Having taught the class for 8+ years, I was presented with a novel situation: the hospital was a brand-new MEDITECH 6.1 client, having switched from another system entirely.
Not only did they not know about Data Repository, but they had no familiarity with how MEDITECH works and what "BAR" or "REG" even mean. So, before you can learn about DR and SQL, it helps to have a basic understanding of MEDITECH and its applications too.
The MEDITECH EHR works by separating and integrating all the clinical and administrative functions into component applications (sometimes referred to as "modules"). These applications are typically referred to by their shorthand "mnemonic" or abbreviation: Registration becomes REG; Admissions becomes ADM; Billing/Accounts Receivable is BAR; Laboratory is LAB, and so on.
From a report writing perspective, it's helpful to categorize information based on what you might need to satisfy a report. We often group information accordingly for our most commonly written reports:
1. Patient demographics and account-level data. You almost always need patient demographics (name, address, etc.) as well as their account number and or medical record/unit number. This can be found in the REG and HIM (Health Information Management) applications, with REG providing visit or encounter-level info (e.g. account number, admission date) and HIM providing patient-level info (name, address, gender, etc.).
2. Codified and abstracted data. After a patient visit, we need to codify the records, so bills can be produced and procedures identified for insurance purposes, etc. This happens in Abstracting (ABS), where DRG codes are assigned to procedures and diagnoses, and within BAR, which records detailed charges, codified CPT codes and billing summary and detail. These data are also stored at the visit level, with additional transactional information available too (e.g. a list of all charges for a visit).
3. Clinical information. We use this to describe the activity within MEDITECH where your providers, nurses, clinicians, pharmacists and technicians are documenting the patient stay. The most common applications we use here include the Patient Care System (PCS, where providers and nurses do documentation); Laboratory (which includes LAB, MIC, BBK and PTH); medication information from Pharmacy (PHA); Order Management (OM) for any procedures and medications that are ordered; Surgical Services (SUR); Imaging and Therapeutic Services (ITS) and Emergency Department Management (EDM). Again, we can relate this activity to the patient visit level from each of these applications.
The applications and categories as I've described them above are by no means exhaustive. MEDITECH has other clinical and financial applications too, including Accounts Payable, Human Resources, General Ledger, Ambulatory and Home Care. As a starting point, these are what we use in practice for most of our report writing.
MEDITECH application data are captured and stored in the system's proprietary file structure. It's important to note that Data Repository is basically a copy of this information stored in a SQL Server relational database, a physically separate system that is designed to receive ongoing data updates. This transfer from MEDITECH to SQL Server is one-way: the DR is a read-only copy of MEDITECH information, updated continuously in near real-time. (For an overview of how this system works, I recommend logging in to the MEDITECH Customer Service portion of their website, then searching the DR Resource Center for "data transfers.")
The benefit of using DR as a reporting platform is twofold: firstly, since we're reporting off a copy of the data on a physically separate server, we're not impacting the EHR system by running lots of reports. Second, since SQL Server is a relational database system, we can now access the data using standard tools and software, rather than having to learn Report Designer or NPR.
The most basic logical data storage entity in any relational database is a table. If you've ever worked in a spreadsheet, you've worked with a table of sorts. Like a spreadsheet, database tables contain rows of data (or records) that are related to each other, based on some type of unique identifier. For example, a table of patients might identify each record uniquely by medical record number, some value that can only exist once, since we can't have two patients with the same number. A table of zip codes would only have each zip code stored once, but also have other information stored in the same record (e.g. City, State, etc.). Each segment of a row is called a column (sometimes referred to as a field): while rows are horizontal and represent each column value for a single record, the columns are the vertical representation for every row in the table.
At first glance the sheer number of tables in a typical 6.1 DR can be intimidating: over 18,000 between two databases. (MEDITECH 6.0 and 6.1 separate their systems based on two technologies: Client/Server, or NPR; and MEDITECH Advanced Technology, or M-AT. The DR reflects this structure with two databases, typically livefdb and livendb.) In 6.1, most of the applications use the newer M-AT technology (the "f" database); some older clinical applications (most notably LAB and PHA) still use the older NPR technology ("n" database).
Regardless of which underlying technology is used, the DR table naming convention follows MEDITECH's model of storing data based on the application it belongs to: Registration (REG) data will flow to tables whose names start with "Reg," Abstracting data (ABS) will flow to "Abs" tables, LAB to "Lab" and so on. You'll note that every database object and the data itself are always case sensitive in DR.
After the initial 2 or 3 letters, DR table names will describe the data they contain, often with some indication as to the level of detail too. A simple example from the livendb is LabSpecimens, which holds specimen-level data (one row per unique specimen, as in a blood draw). LabSpecimenTests then is where we find data about each test and result associated with that specimen, which will have many records (tests) per specimen. This type of relationship is intentionally hierarchical, and often described as a "parent-child" relationship. You can't have a lab test record if there's no parent lab specimen record.
Further, starting with their 6.x platform, MEDITECH introduced the use of the underscore character in SQL tables to logically separate types or groups of data, as well as the convention of naming key parent tables with the "_Main" designation. (We sometimes refer to these as "top-level" tables, which tend to make good starting points for your reports.) For example, for any report that requires patient account information, we'll start with RegAcct_Main. From there, we can get other related data from REG: RegAcct_Registration for the admit source, RegAcct_Providers to get information about their attending physician, and so on.
This naming convention and structure applies to both DR databases, and is our first indication as to where to find certain types of data. Here's a snapshot list of commonly-used tables, which are the building blocks for many reports:
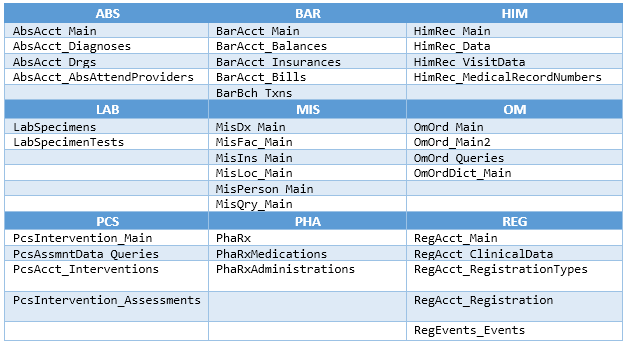
It's rare that you'll write a report that only needs information from one application in MEDITECH. Let's illustrate this with a simple example: an inpatient census by location report. We want the following fields displayed: the inpatient facility and location names, patient name, account number, admission date, medical record number, DOB, gender, patient room and bed. Since the information will come from several MEDITECH applications (REG, MIS, and HIM) our list of required tables will include:
As you can see, even for a simple report, we're going to bring together data from multiple applications, sometimes described as "cross module" reporting. This is accomplished in T-SQL code by using a technique called "joining," where you define the columns from one table that JOIN (or match) the columns from another related table. (For further reading on this, please see this blog on primary keys in DR.)
Once you begin to grasp how information in MEDITECH is organized, and have some basic understanding of which applications provide what functionality, you can explore the DR data structures with more confidence. Over time you'll develop your own knowledge and expertise and realize the full value of the DR as a primary data source for your organization's reporting needs.



