I often find myself having the same conversation with folks about the health of the data in MEDITECH’S Data Repository (DR). I remind them that if they use the DR for reporting, but don’t have a process to maintain data health and accuracy, then they shouldn’t be using DR. Keeping DR data healthy is easy, it’s just a matter of knowing what to do and when to do it.
I’ve put together some of the more common guidelines our consultants use on a daily basis.
 Best Practices
Best Practices
When done on a regular basis, certain tasks ensure that DR data remains accurate, and that updates and reporting are as efficient as possible. Keep in mind that “reporting” can be a simple SQL query, executing stored procedures with SSRS, BCA, or Power BI, using data marts to export data, and so on: reporting can be any application that uses the DR data.
We recommend the following items be addressed on a regular basis for the DR server:
- Monitor free and used drive space (weekly)
- Performing regular index maintenance (defragmentation)
- Monitoring the data transfer background jobs (daily)
- Monitoring pending DR transfer activity (daily)
- Reviewing data transfer errors and submitting tasks to MEDITECH when required to address these errors (as needed)
- Perform regular data validation on core DR tables (with MT or third-party tools)
- Performance analysis of your DR to identify the following:
- Queries that cause excessive blocking
- Queries with excessive I/O (disk reads/writes)
- Queries with excessive CPU usage
- Queries with multiple transactions open at once
- Ineffective or improperly built non-clustered indexes
In a perfect world, the tasks mentioned here would be handled by an IT staff member (a DBA, for example), but since many facilities lack that capacity, outside vendors like Acmeware commonly take them on for you. We have developed our own utilities and best practices, including a DR Health Assessment Tool that does a comprehensive analysis of your DR server’s configuration, operation and performance. (See our Partnership Program page for more information.)
How data gets to Data Repository
Because of the MEDITECH EHR’s system architecture, it helps to understand how data are created in the DR SQL Server databases. Remember that DR is effectively a read-only copy of transactional data from the EHR. As depicted in the simplified system diagram below, as end users work in MEDITECH applications, the data changes are queued up and sent to SQL Server, where native SQL INSERT and UPDATE statements recreate the data in the relational live and test databases. (The diagram is for 6.1/Expanse systems, but conceptually, the process is the same for MAGIC and C/S.)
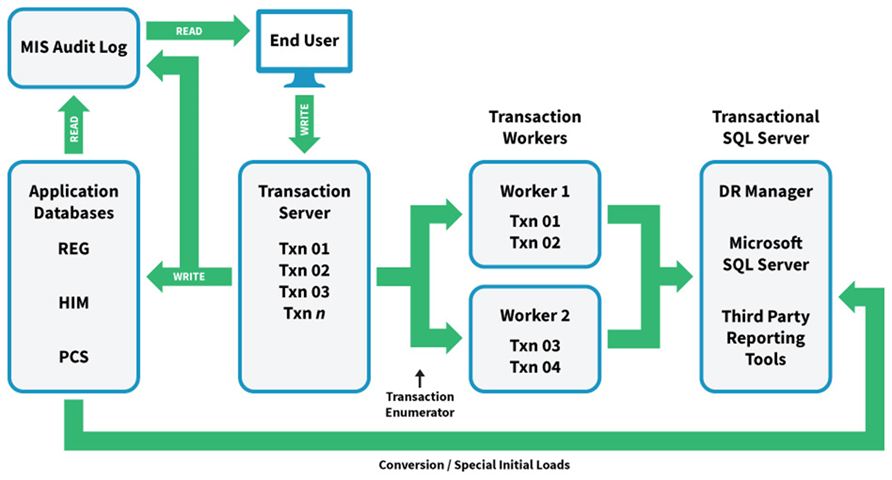
Because of the sheer volume of data that’s added and constantly updated in MEDITECH, and the necessity of duplicating it in the DR database, it’s important to monitor and troubleshoot both the background jobs responsible for handing the data transfers, as well as practicing good maintenance within SQL Server too – there are in fact two separate systems to maintain.
Background Activity in MEDITECH
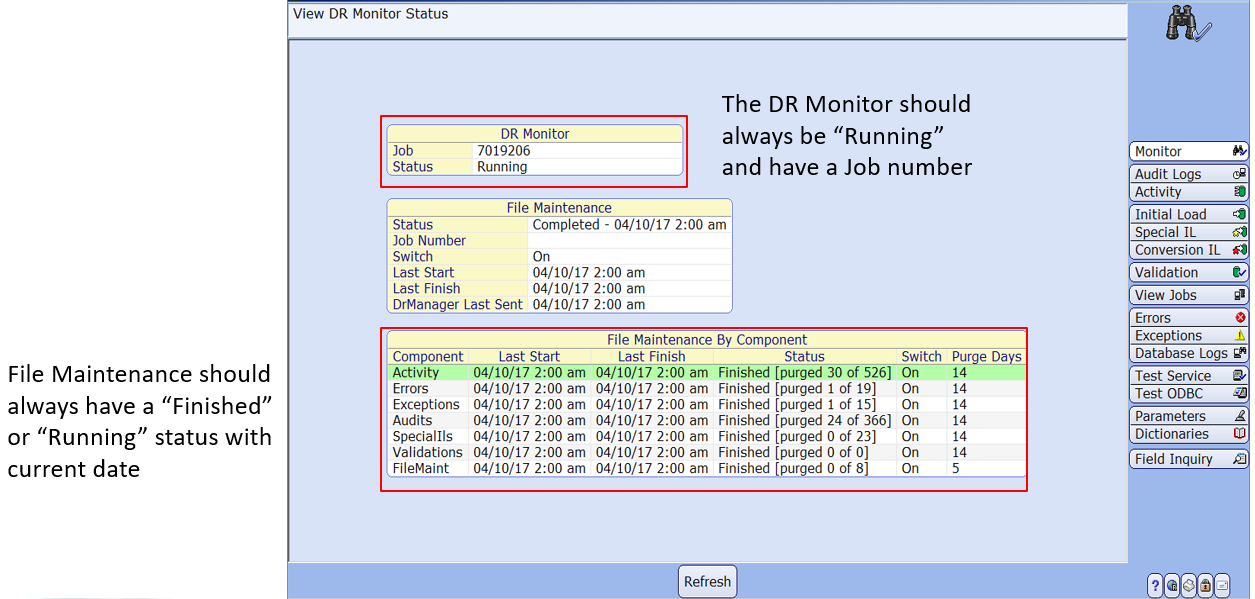
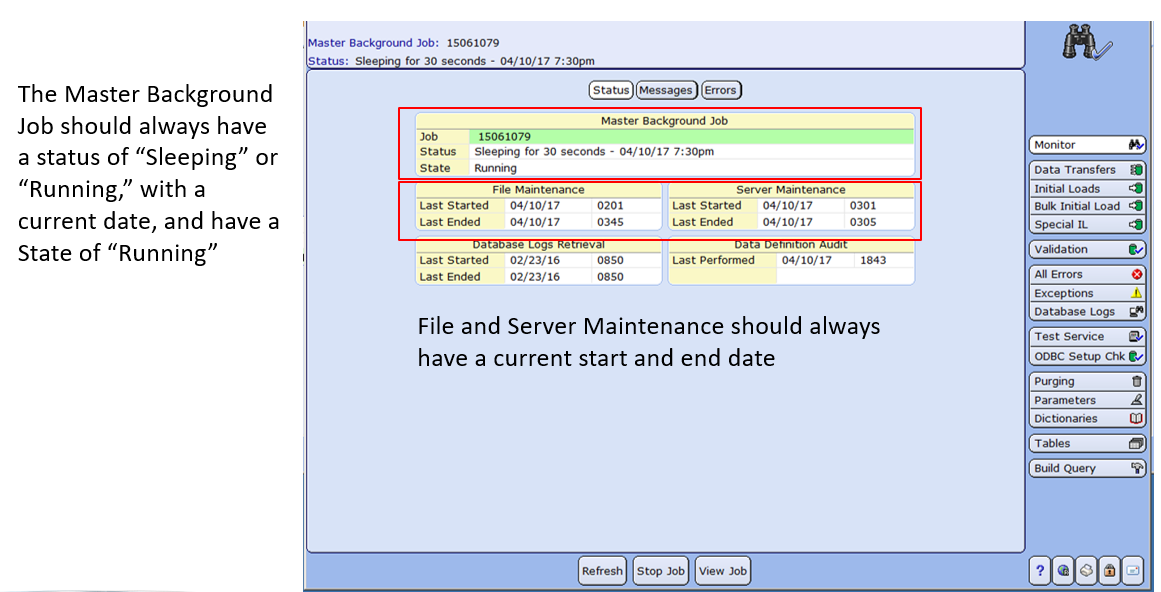
There are a couple of important routines in MEDITECH’s Data Repository application you can use to maintain DR-related processes. They include the DR Monitor (6.1/Expanse) and Master Background Job (C/S and MAGIC), and the File Maintenance job status. See the screenshots below for more details.
For Expanse/6.1
For Client/Server
DR Transfer Errors
In both Expanse and C/S (and MAGIC), the data transfer process logs every step of the process, and reports what are categorized as “errors.” Not every message however is truly an error, so how do you determine which require investigation, and which you can safely ignore? We don’t recommend reporting every error to MEDITECH, unless you want to ruin your relationship with your DR specialist! Some of the common errors that are worth following up on include:
- Primary key missing. This occurs when data are filed to the DR Activity Index. Since SQL requires all primary keys (PKs) to be present and MT does not, this can potentially lead to data not being written to DR.
- Missing subscripts in activity. Occurs in the MEDITECH data structure during data capture and should be investigated by MEDITECH.
- Skipped sequence errors. Very commonly the network connection is interrupted while a sequence is sending. The sequence is “skipped” and must be resent. Data will not populate the table until the activity is sent. These sorts of errors are time-sensitive and should be reported as they occur; MEDITECH are able to resolve them quickly.
- ODBC non-fatal errors. These occur if the records are not in the SQL table.
- Socket errors. These occur when the transfer process can’t connect to the DR SQL Server. If these occur repeatedly and do no self-resolve, it’s usually an indication that the server is offline.
SQL Server Considerations
There are two primary areas of focus on SQL Server maintenance for Data Repository, both related to the ongoing data transfer process: database growth (and its impact on disk drive storage) and maintaining SQL table query efficiency with regular index defragmentation.
Database Growth & Storage Capacity
Unlike the MEDITECH EHR, data does not purge from the DR. Over time, the DR databases (both test and live) will consume more and more disk space. Since both MEDITECH and Acmeware recommend that every DR table be enabled for data transfer, this will require significant storage space, but gives you full historical reporting capability, regardless of the application purge parameters. This of course means a system administrator should always be monitoring free disk space on your server, regardless of what type of storage it uses. When available free space for the drives dedicated to the DR databases falls below 20%, it’s time to plan to add more capacity.
Selectively, in order to save disk space, there are some large tables that can be disabled for data transfer. Take ItsResultText, for example. It is actually a duplicate table to ItsResultFreeText and includes embedded formatting characters, making it unhelpful for reporting, so we typically ask MEDITECH to turn it off and truncate it to avoid confusion and reclaim space on the DR server. There are other high-consumption tables that can be safely disabled; but work with your DR specialist before doing this.
Table Index Maintenance
As new data are continually added and updated to DR tables, over time the tables can become fragmented – that is, the physical data storage structures on disk use space less efficiently. Analyzing index fragmentation for every table and performing index reorganization or defragmentation are highly recommended for more efficient storage and faster data retrieval.
Fortunately, the metadata within SQL Server is available by querying both system tables directly, and by using system management views that Microsoft provides. For example, the following query shows all indexes from testfdb with a fragmentation level greater than 15%:
use testfdb
go
SELECT
pt.index_id,
i.name AS IndexName,
pt.avg_fragmentation_in_percent AS PctFragmented,
t.name AS TableName
FROM
sys.dm_db_index_physical_stats (DB_ID(N'testfdb'), OBJECT_ID(NULL), NULL, NULL, NULL) pt
INNER JOIN sys.indexes i
ON pt.object_id = i.object_id
AND pt.index_id = i.index_id
INNER JOIN sys.tables t
ON i.object_id = t.object_id
WHERE
pt.avg_fragmentation_in_percent > 15
ORDER BY
t.name
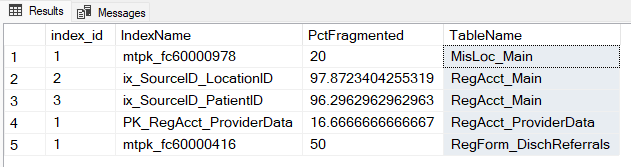
As these results show, you can see that 3 of the 5 indexes returned are highly fragmented (50-97%) and should be corrected. The most effective way to do this is by rebuilding the index. Here’s how we would address that for a single table:
ALTER INDEX ALL ON testfdb.dbo.RegAcct_Main REBUILD
By using variations for these simple queries, you can address index fragmentation by scheduling jobs to analyze all indexes in a database and act on those that exceed a certain threshold. Once you’ve done this for an entire database, the automatic process can maintain your indexes with almost no intervention or system impact.
I hope you have found the above information helpful as you work to maintain a healthy Data Repository for your organization. Please don’t hesitate to contact us if you have any questions.