I recently had a student from one of our online training sessions email me a few days after class, asking why I recommend always using the SourceID column as part of every TSQL join. They sent two queries to demonstrate why they felt they shouldn’t use SourceID.
The first query joins only the PatientID (part of the primary key for both tables):
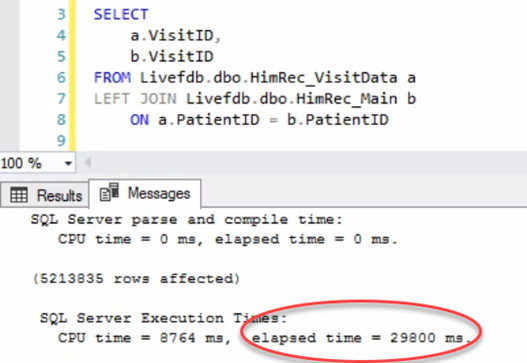
The second query is identical, except adds the SourceID (also part of the primary key) to the join:
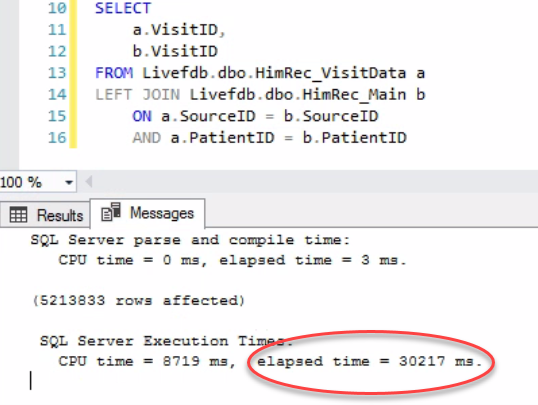
I can hear them now, triumphant: see, it’s faster without the SourceID! Hold on a moment, I say, let me explain. But first: what exactly is the SourceID?
The SourceID
When you look at the data stored in every SourceID column, in every Data Repository table, it’s only 3 letters, most often, MEDITECH’s mnemonic for your organization. For most people, this value will always be the same, in every row of every table, so it’s logical to question why you would need to specify it in a SQL join.
MEDITECH uses the SourceID to accommodate organizations whose hospitals may roll up to a corporate parent, or other scenarios where the need to distinguish data from different HCIS’ are stored in a single Data Repository. In other words, there are occasions, that don’t apply to every hospital, where the data values could be different within a single DR. (For a more detailed discussion, see the MT KB article on SourceID.)
Now that we know why it’s there, I can give you the short and long version of why you should use SourceID in your joins. First, the short version: because I said so. OK, what I really mean is that using it is the standard and accepted way to do it by every vendor and “professional” developer for Data Repository. And for good reason. Which leads me to the longer answer, so read on for details.
The long version
The example from my student is not a realistic workload. The measured time of each query is similar because the query is simply returning all rows from both tables, with no criteria whatsoever. In effect, that query tells SQL Server to read all rows from both tables and scan the clustered index to do so. You don’t see that, but that’s what happens under the hood. There’s a feature in SSMS you can use to see the query execution plan and it will show you how the data are being queried, sorted, and presented (the red arrows are mine):
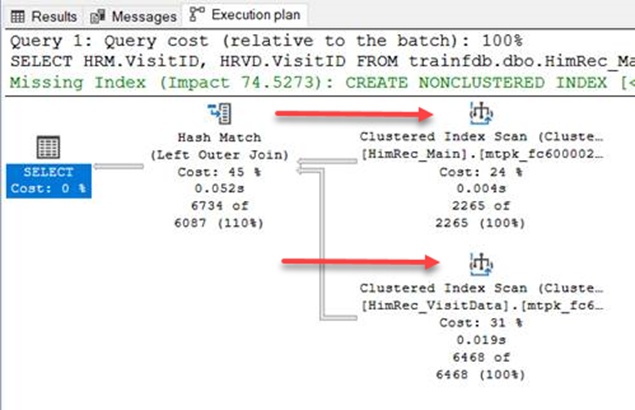
This plan doesn’t change with or without SourceID in the join since it still has to read all rows from both tables by doing a clustered index scan – so there is no performance gain by using the SourceID. A clustered index scan, by the way, is not terribly efficient, as it scans the whole index to find the rows of interest, in this case, every single row.
However, if we use a realistic example, by adding a JOIN to RegAcct_Main (odds are if I’m looking for patients and visits in HIM, I’m going to want some data from REG, like account number) we can see how the query behavior differs by joining (or not) with the SourceID.
First, my updated query, which is very typical for any patient visit-based report (the name, account number, and medical record number):
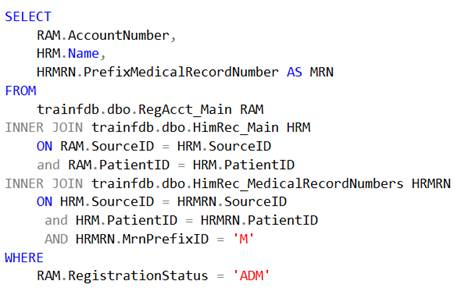
Note that I’ve added a third column to the join to HimRec_MedicalRecordNumbers, which includes the prefix – part of the primary key. By doing so, I’m including each of the 3 key columns in the join. I’ve also added a criterion (registration status) from RegAcct_Main to illustrate the likelihood of needing data from this table (it could be Status, date-based, etc.).
When I include the SourceID in every join, it results in this query plan:
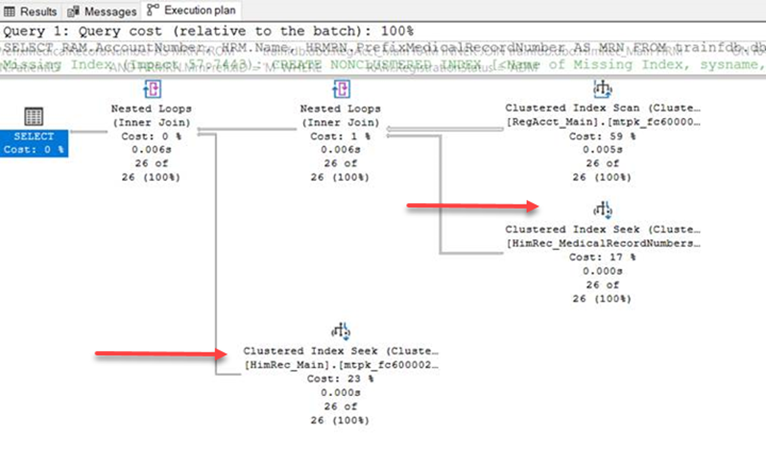
Note that the data from the two HIM tables are now being retrieved with a “Clustered Index Seek,” which is a much more efficient operation. As the little symbol suggests, the rows that meet the criteria are the only ones being read from those tables, not all of them via the index scan operation. My test data table won’t show a total execution time difference (it only has a few thousand records), but if you run this against live data, you will likely see a noticeable difference.
Finally, if I run my modified query without joining on SourceID, look what happens:
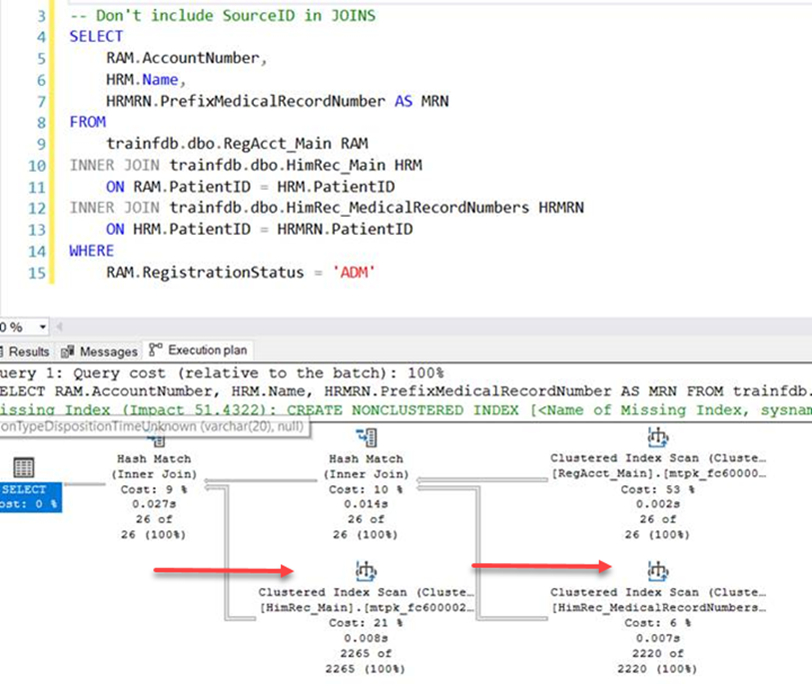
Scans across the board, which are less efficient and will take longer to execute.
If you’ve read this far…thanks for hanging in there. The moral of the story for you and your team is…yes please, join on the SourceID!